
12月28日,医学影像分析领域顶级期刊IEEE Transactions on Medical Imaging (影响因子6.69,中科院一区)发表了本实验室硕士生王璐、郭栋同学在降低深度学习医学图像分割模型对标注数据的依赖方面的工作“Annotation-Efficient Learning for Medical Image Segmentation based on Noisy Pseudo Labels and Adversarial Learning”。该工作对于减少深度学习模型的训练过程中对大量标注数据的依赖,提高人工智能图像分割模型的开发效率,降低标注数据的获取成本具有重要意义。
医学图像分割对于疾病诊断、病灶定量分析、治疗计划的制定等具有重要意义。目前基于深度学习的方法在医学图像的自动分割中取得了优越的性能,但是它的成功依赖于海量的人工标注的图像进行训练,即每幅训练图像需要有对应的分割标注掩码。在医学图像分割任务中,对一幅三维图像的像素级别的标注通常需要数小时,并且需由有较深领域知识的医生来提供。这个标注过程非常费时而枯燥,现实场景中医生通常没有时间和精力来完成这样的大规模标注。因此,对大规模高质量的标注数据的依赖,已经成为深度学习图像分割算法的研究和应用中面临主要障碍之一。
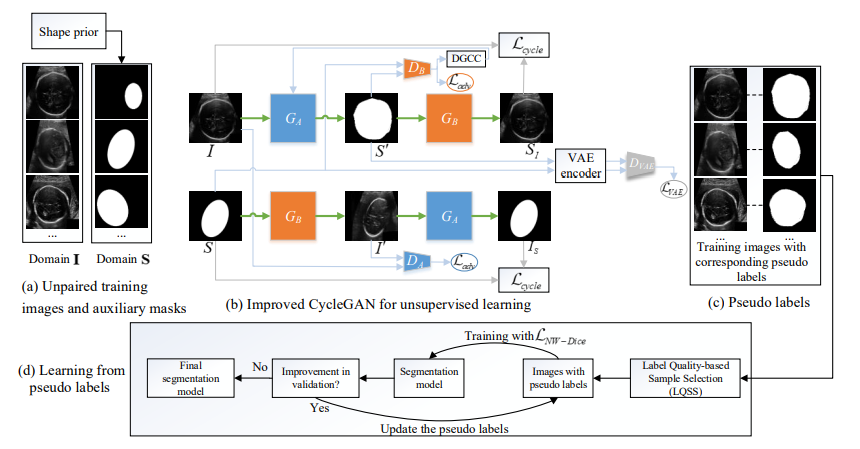
针对这个问题,王璐、郭栋同学在王国泰老师的指导下,提出一种新型的具有标注高效性的学习方法。该方法不需要训练集中的图像具有与之对应的标注掩码,而是利用形状先验信息或者第三方公开数据集中的分割掩码(与训练集中的图像没有对应关系)作为辅助,训练深度学习模型实现医学图像的精确分割。在辅助掩码的帮助下,通过改进的循环一致性对抗网络生成每一幅训练图像的伪标签,然后通过一个对噪声鲁棒的迭代学习方法从伪标签进行学习,最终得到高性能的分割模型。
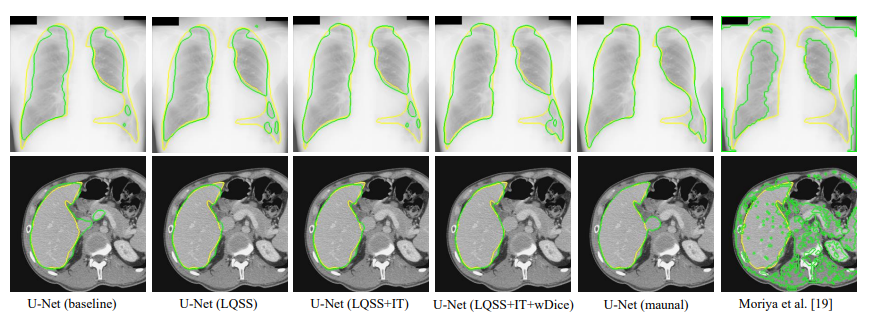
本文通过对胎儿头部、视盘、肝脏、肺等多个器官进行分割实验,结果表明所提出方法明显优于现有的基于弱监督、无监督及域适应等技术的方法,以及基于霍夫检测、主动轮廓模型等传统的图像分割方法。本文提出的方法不需要对训练数据进行逐个标注,并且取得了与从人工标注中进行学习相媲美的性能(上图第四列和第五列的对比),使得仅使用大量的未标注数据和第三方掩码进行学习成为可能,克服了深度学习模型对标注依赖的瓶颈问题。
本研究成果由电子科技大学与商汤科技等单位合作完成。第一作者王璐同学是本实验室2019级硕士生,本论文也是她首次发表的研究成果。
论文链接:https://ieeexplore.ieee.org/document/9309350
手机浏览
公众号
访问量: 开通时间:-- 最后更新时间:--
清水河校区:成都市高新区(西区)西源大道2006号 邮编: 611731
沙河校区:成都市建设北路二段四号 邮编:610054
蜀ICP备 05006379 号 I 川公网安备 51019002000280 号
